
A product manager needs to make a critical roadmap decision. He remembers research from two years ago that's directly relevant — but not which study, not which report, not which folder it lived in.
A designer needs to defend a decision to a skeptical stakeholder. She knows past research supports her position — but can't surface it quickly enough to matter.
These weren't edge cases. They were Tuesday.
Research insights were being generated continuously: studies completed, findings documented, patterns emerging across projects. But the knowledge lived in static reports and a rigid query tool that could only return what it had been explicitly told to surface.
The data was there. The decisions died.
This case study is about changing that.
Three bullets and a link.
IBM Security had a research repository — a query tool built on Airtable, used across the security portfolio. Researchers logged each completed study: the name, date, product area, product, a link to the full report, and a bulleted list of what they determined were the top three insights.
On paper, it was a knowledge base. In practice, it was a filing system with a search bar.
Querying it required knowing what you were looking for. Most people didn't know the study name. They knew a product area and a vague memory of something relevant. So searches amounted to a product area plus a few keywords, returning a snippet: study name, date, researcher, product area, product, a link, and those three bullets.
Three bullets. Chosen by the researcher. Mandatory. Final. A study might have uncovered eight significant findings, but only three made the list. Selected by one person, on one day, with no way to anticipate what a colleague might need two years later.
Whatever didn't make the list stayed in the report. Locked behind a link most people didn't have time (or will) to open.
When the tool failed to provide what was needed — and it often did — people Slacked the researcher directly. If they still worked there. If they even remembered.
That was the system. It wasn't broken. It was just built for a world before AI made something better possible.

Intelligence in waiting.
The research sitting inside those reports represented years of direct contact with real users: their frustrations, their mental models, their unmet needs, their moments of clarity. That knowledge had the potential to inform decisions already being made — and ones nobody ever saw coming.
But potential isn't the same as impact. Knowledge that can't be reached doesn't influence decisions. It just ages.
The opportunity wasn't simply to build a better search tool. It was to transform how institutional knowledge moved through a product organization. It was to go from a static archive that rewarded persistence and personal connections, to a living resource that anyone could access, in the moment they needed it, with the full depth of what the organization actually knew.
Better access means better-informed decisions. A PM who could instantly surface what users said about a pain point two years ago, makes a different roadmap call than one who relies on memory or skips the reference entirely. A designer who could pull cross-study evidence in minutes, walks into a stakeholder meeting with a fundamentally stronger position.
And there was a second beneficiary: the researchers themselves. Every Slack message asking "do you remember what we found about X?" was a fragment of deep work interrupted. It was a tax on the people best positioned to generate new knowledge rather than retrieve old knowledge. An agent that answers those questions autonomously, would give researchers back their focus to do the work only they can do.
The goal wasn't just convenience. It was compounding intelligence — so that knowledge gained could pay dividends long after the findings that generated it were complete.
From archives to answers.
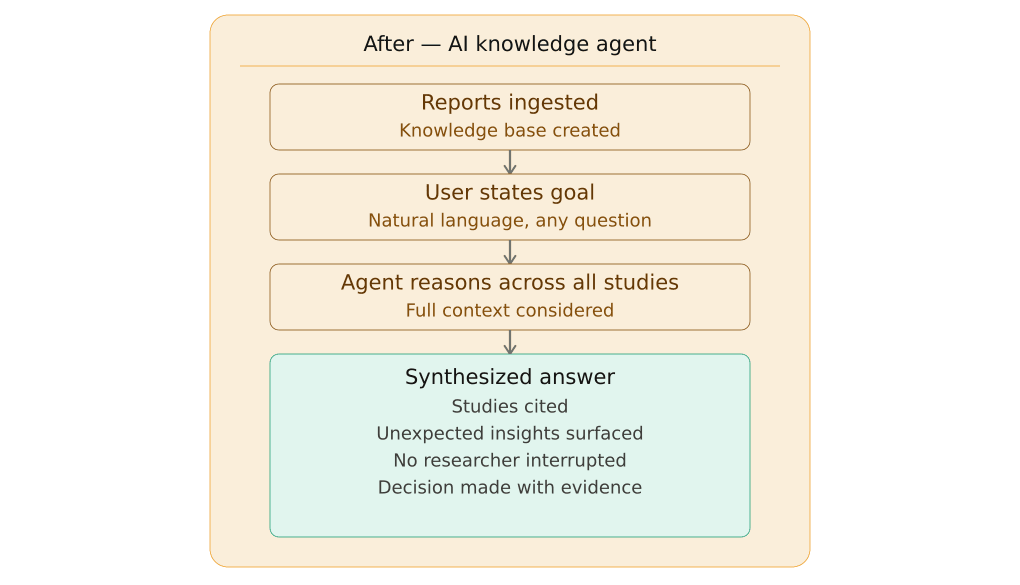
The build started with a question that shaped every decision that followed: What does this agent actually need to do?
The answer wasn't "search research reports." Search already existed. The Airtable tool was search — constrained, rigid search, but search nonetheless. What was needed was something fundamentally different: an agent that could reason across a corpus of knowledge, synthesize findings from multiple studies simultaneously, and return answers that reflected the full depth of what the organization knew. Not just the three bullets someone chose to enter years ago.
That distinction — retrieval versus synthesis — drove every architectural decision.
The corpus
The foundation was research reports spanning IBM Security's portfolio. These studies covered compliance workflows, data classification, user onboarding, privacy management, and security posture monitoring, among others. Before ingestion, each report was reviewed and scrubbed of personally identifiable information.
The approach
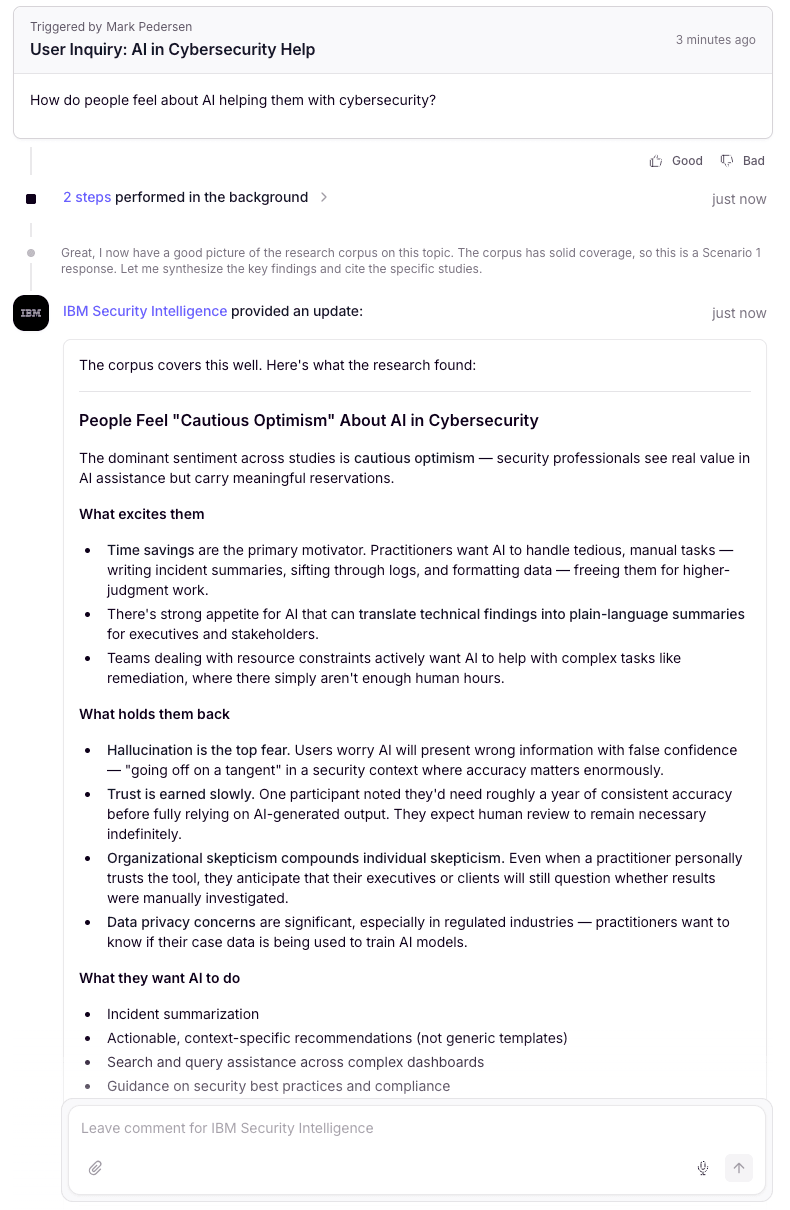
Rather than building a document retrieval system that returns files, the agent was configured to read across the entire corpus and generate synthesized responses grounded in the actual content. A question about user attitudes toward compliance doesn't return a link to a study. It returns a synthesized answer drawn from every relevant study in the corpus, with the underlying sources identified.
This matters because the most valuable insights rarely live in a single study. Patterns emerge across studies. Contradictions between studies are often more instructive than the studies themselves. An agent that reasons across the corpus rather than within a single document surfaces that layer of intelligence: the layer that the Airtable tool could never reach.
The design decisions
Four deliberate choices shaped how the agent behaves:
Synthesis over retrieval: the agent generates answers, it doesn't just return documents. This was the core design principle and everything else flowed from it.
Citation over assertion: every response identifies which studies informed the answer. This wasn't just about accuracy — it was about trust. An enterprise knowledge tool that makes claims without sources isn't useful, it's dangerous.
Transparency over confidence: the agent was built to surface insights from the research corpus, not to simulate one. When coverage is thin, the agent supplements with general knowledge, powered by Claude, and discloses that distinction explicitly.
Privacy over attribution: the agent is instructed not to surface the names of individual researchers or study authors. Findings are attributed to the study itself, keeping the focus on the evidence rather than the people behind it.
Conversation over query: the agent employs the Flipped Interaction Pattern, opening by asking about the user's underlying goal. Understanding the decision someone is trying to make produces more targeted and useful responses.
The platform
The agent was built and deployed in Relevance AI: a no-code platform purpose-built for enterprise AI agents. This choice was deliberate. A tool that business users can own, adjust, and build on. No engineering required.
Relevance AI mirrors the deployment reality of enterprise AI: accessible, configurable, and built to empower the people closest to the problem.

Trust but verify.
The agent was evaluated against the four response scenarios built into its design — testing whether it correctly distinguished between full coverage, partial coverage, no coverage, and out-of-scope queries. Across all four, it behaved as intended: surfacing research when it existed, disclosing limitations when coverage was thin, and redirecting clearly when a question fell outside scope.
Citation behavior was the most important thing to get right. Early testing revealed that the retrieval layer was returning content without preserving source document names — meaning the agent could synthesize findings but couldn't tell you which study they came from. Resolving this required switching from standard RAG retrieval to an Advanced Knowledge Search tool that loads full document context, giving the agent the information it needed to cite specific studies by name.
The agent also demonstrated coherent reasoning across a conversation — connecting a follow-up question about common databases back to the user's earlier GDPR roadmap context without being prompted. That kind of continuity matters in a real customer interaction.
The agent demonstrates adaptive citation behavior — matching its sourcing approach to the structure of the evidence. When a finding traces cleanly to a single study, it cites inline. When multiple studies converge on the same insight, it synthesizes and lists sources collectively. And when a user wants to go deeper on a specific finding, it can drill into the source study on request. That kind of judgment — knowing when to show your work and when to get out of the way — is what separates a useful research tool from one that buries the user in footnotes.
Value realized.
What started as three bullets and a link is now a working research intelligence tool — one that any product team member can query in plain language and get synthesized, cited answers. No search terms. No document navigation. No institutional knowledge required.
But this is how AI is supposed to be designed — for the humans that use it.




